Building an AI audiobook that people actually want to listen to
Today I'm launching the audiobook edition of Inference Engineering. It is narrated by AI because I felt that using AI would let me deliver the highest possible quality.
Authors have three options for creating audio editions of their work:
- Record themselves reading the book
- Hire a professional to narrate the book
- Use AI to synthesize the book as audio
I wanted to ship a great audiobook, and I wanted it in my voice. As an engineer, I trusted more in my ability to build a pipeline for getting fantastic quality with AI than in my vocal talents in a recording studio.
Fundamentally, text-to-speech models are not designed for long-form audio. They're optimized to deliver low latency and short sequences to voice agents. But when my friends at Rime demoed their then-unreleased Coda model to me, I knew it would be possible to create a great listening experience using an AI voice.
My goal in this project was to create an enjoyable listening experience that matched the precision of a professional narrator with the style and cadence of my own voice. To accomplish this, I had to solve four problems:
- Replicating my voice with a text-to-speech model
- Translating diagrams, tables, and equations into words
- Chunking a book's worth of text into reasonably-sized API calls
- Assembling output audio into valid audiobook files
I'll let you be the judge of the final product, though I will say I'm happy with how things turned out. You can download the audiobook edition of Inference Engineering for free on the Baseten website.
Voice cloning with Rime's Coda TTS model
Rime's Coda model is fantastic. I was excited to work with Rime on this project because their team starts from the craft of language and figures out how to apply it to AI, not the other way around.
Coda, their latest base model, is highly expressive and natural. It uses dual autoregressive decoders, trained in conjunction, to excel at both semantic and acoustic understanding. The model is specifically designed for conversation. An audiobook is not a conversation, but I hoped the model would reflect the conversational tone of my writing.
Broadly, there two approaches to voice cloning:
- Zero-shot voice cloning: generates an approximation of a voice using an unlabeled sample of a few seconds to a few minutes of speech.
- Full voice cloning: generates a highly accurate impression of a voice using minutes of hours of labeled voice data.
I went through Rime's enterprise voice cloning process to create a high-fidelity representation of my voice in the Coda model. This involved a 30-minute studio recording session where I read passages from the book with a focus on paragraph-length chunks and hitting inference-specific vocabulary words.
From there, Rime's post-training team took the text of the book, matched it to a cleaned and edited audio recording, and began the fine-tuning process.

The Rime team fine-tuned Coda to match the exact register, pitch, cadence, and every other detail of my voice. The final model so accurately matches my voice that when I was testing it at home, members of my family thought I was speaking on a call, not listening to an audio sample.
Preprocessing input text and images
Written language guides the reader on pacing and structure through punctuation, spacing, and various other linguistic features. Text-to-speech models mostly use the same guidance, but have their own quirks in how they interpret punctuation and spacing that must be addressed for AI-generated speech to flow naturally.
Inference Engineering also contains over 100 carefully-designed charts, graphs, images, tables, and other purely visual features. These additions are essential to the content and style of the book.
For the audiobook, I had three options:
- Omit the visual elements entirely
- Provide a comprehensive description of each visual
- Weave references to the visuals into the main text
I chose the third option. Given that the PDF is freely available and each figure is labeled and captioned, it's easy for a listener to reference any diagrams they are interested in, and the narrative flow is not interrupted by long descriptions of visual assets. Similarly, lists, tables, and other text-heavy visual features are reworked into simple prose to work in the audio format.
This is a multi-step process. Starting with the full text of the book in Markdown, I manually stripped out the appendices, frontmatter, and backmatter. Then, I ran a three-step pipeline:
- Use Python for deterministic chunking, cleaning, and organizing of the text into 136 subsection-level files of a few hundred words each.
- Use LLMs with a clear system prompt to revise each file to address the image and structural text issues explained above as well as provide consistency across punctuation and style.
- Use Python on the LLM outputs to ensure accuracy and adherence to model-specific rules (e.g. re-write "Baseten" as "base ten" for proper pronunciation)
As is often the case in AI, it's the cleanliness of the inputs that determines the quality of the outputs.
Generating the audio
With all of the text chunked and cleaned, generating the audio was fairly straightforward.
Text-to-speech models generally work best with at most a paragraph of text at a time. This gives enough context for continuity across sentences but doesn't give the model much space to go off the rails. Because the input text was clean, a simple API-call-per-newline loop was sufficient to generate the audio, with a script at the end to stitch the files together. I had the model output WAV files for the highest quality.
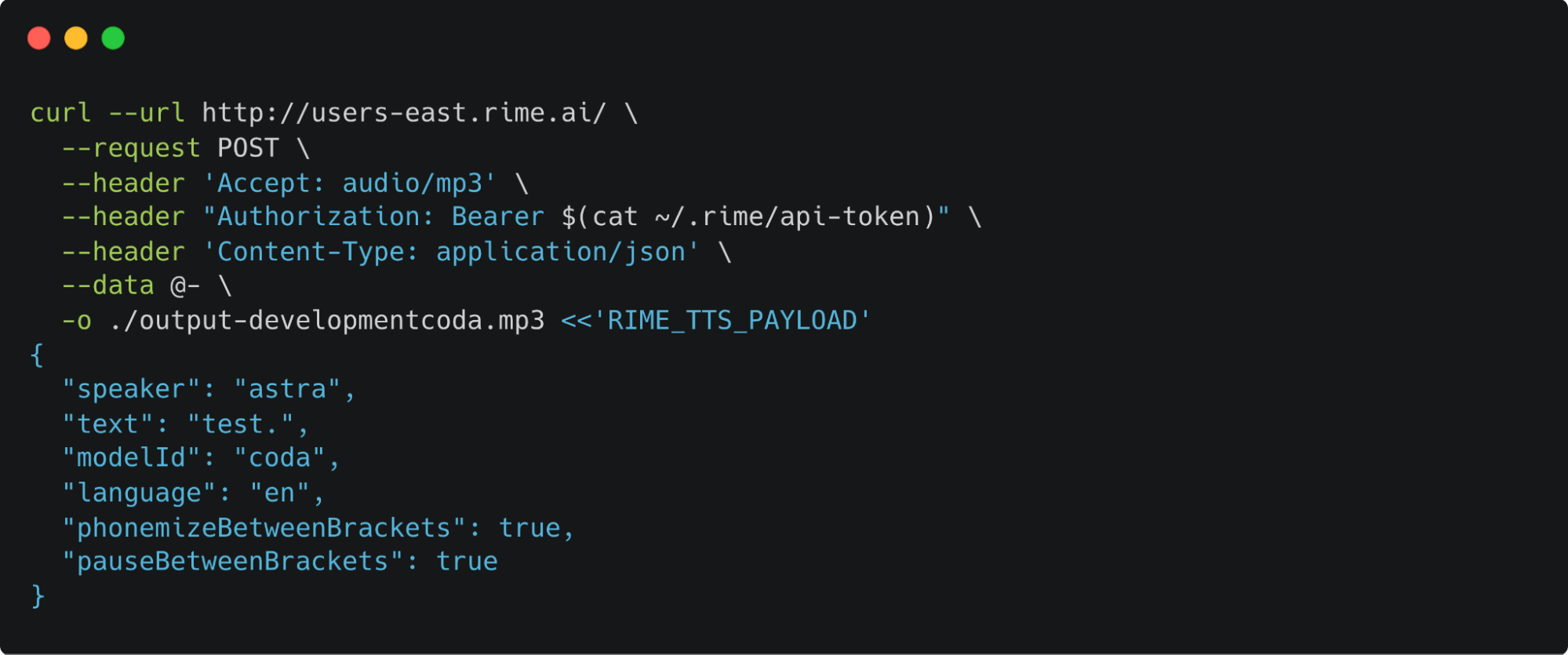
All in, a single run of the audiobook generation pipeline from scratch cost less than twenty dollars on the Rime API for Coda.
Assembling the audiobook
Before starting this project, I knew nothing about audiobook file formats. Turns out, you can't just ship inference.wav and call it a day.

Fortunately, I already had the book chunked at its existing section-level headers to generate the intermediate audio files. This meant I didn't have to do any manual annotation to create chapters.
Instead, I simply asked Cursor to build a spec for an Apple Books-compatible audiobook as well as a backup folder of chapter-by-chapter MP3 files for other players, then implement a script to convert my output files into the specified format.
The agent did a great job. The final output file is an M4B of less than 200 MB with perfect chapter alignment and metadata.
A reflection on this project
I don't think I saved much time or money using AI, at least not if the goal was a single audiobook. It took a couple of days of agent-assisted engineering work to build the audiobook pipeline and review outputs, and the cost in GPUs, data annotation, and ML engineering to fine-tuning a custom voice model was not insubstantial.
However, I had a lot more fun learning about audio formats and exploring the boundaries of AI model capabilities than I would have reciting sentences in a recording booth. I'm excited to apply what I learned working on this to future projects.
Additionally, the voice model and audiobook pipeline are now assets that I can use in the future. The training compute and engineering time are fixed costs. If I want to update the book or record a new audiobook, my marginal cost is less than twenty dollars of API usage. A repeatable pipeline that turns text into high-quality audiobooks in my voice is an outcome that I am very happy with.
You can download the audiobook edition of Inference Engineering for free from Baseten and get started with Coda on Rime with plenty of free credits to get you started.